仓库管理系统数据库设计的架构逻辑与优化路径
在数字化供应链高速发展的今天,仓库管理系统(WMS)的效能直接决定企业的库存周转率与运营成本。而支撑这一系统的核心,正是数据库设计——它不仅需要精准映射业务流程,更要具备高效处理海量数据的能力。如何构建一个既能满足实时操作需求、又具备可扩展性的数据库架构?本文将围绕这一命题展开探讨。

一、需求分析:从业务逻辑到数据建模
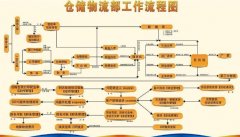
仓库管理系统的数据库设计必须以业务场景的深度解析为起点。库存管理、出入库记录、货位分配、批次追踪等核心功能,均需转化为明确的数据实体与关系。例如,*库存表*需关联商品信息、批次号、有效期等字段,而*订单表*则需绑定客户信息、物流状态及操作时间戳。 在此阶段,实体关系图(ER图)的绘制至关重要。通过定义主键、外键以及表之间的关联规则,可避免数据冗余与不一致性。同时,需考虑多仓库协同场景下的数据分区策略,例如按地域或商品类别进行分库分表设计。
二、数据模型设计:平衡效率与灵活性
数据库模型的选择直接影响系统的响应速度与维护成本。关系型数据库(如MySQL、PostgreSQL)因其事务支持能力与结构化查询优势,常被用于处理库存增减、订单状态变更等强一致性操作。而NoSQL数据库(如MongoDB)则适用于存储非结构化日志或动态扩展的SKU属性。 针对高频操作(如库存实时更新),可通过读写分离与缓存机制降低主库压力。例如,将历史库存记录归档至从库,并在Redis中缓存热销商品的库存余量。此外,*索引优化*是提升查询效率的关键——需针对常用搜索条件(如商品编码、入库日期)建立复合索引,但需避免过度索引导致的写入性能下降。
三、性能优化:应对高并发与大数据量
仓库管理系统常面临多用户并发操作与海量数据累积的挑战。分库分表策略可将数据按时间或业务维度拆分,例如按年度归档历史出入库记录,或为不同仓库分配独立数据库实例。同时,采用异步处理机制可将批量操作(如库存盘点、报表生成)与实时事务分离,减少事务锁竞争。 在硬件层面,SSD存储与内存数据库的应用可显著提升I/O效率。而对于复杂查询(如跨仓库库存汇总),可通过物化视图或预计算聚合表提前生成统计结果,避免在线计算带来的延迟。
四、安全与容灾:保障数据完整性
仓库数据的丢失或篡改可能导致供应链中断。ACID事务特性确保出入库操作的原子性与一致性,而定期备份与异地容灾方案则为数据恢复提供冗余保障。权限控制方面,需通过角色基访问控制(RBAC)限制操作员仅能访问其负责仓库的数据,并记录完整的操作日志以供审计。 对于敏感信息(如客户联系方式、商品成本价),可采用字段级加密或动态脱敏技术。同时,数据库的版本迁移脚本需与应用程序迭代同步,确保表结构变更不会破坏现有业务逻辑。
五、可扩展性设计:适应业务增长与技术演进
随着企业规模扩大,仓库管理系统可能接入IoT设备、自动化机器人等新型终端。数据库架构需预留API接口层,支持与外部系统的数据交互。例如,通过消息队列(如Kafka)接收传感器上报的库存变动事件,并触发数据库的增量更新。 在技术选型上,云原生数据库(如AWS Aurora、阿里云PolarDB)提供弹性扩缩容能力,可灵活应对促销季的流量峰值。此外,采用微服务架构将库存管理、订单处理等模块解耦,可降低数据库的耦合度,便于独立扩展与维护。
通过以上维度的系统化设计,仓库管理系统数据库不仅能支撑当前业务需求,更可为企业构建数据驱动的智能仓储生态奠定基础——从实时库存可视化到预测性补货分析,每一环节都依赖底层数据的精准性与可靠性。





")